I’ve been hosting my blog with WordPress.com for about the last five years for one simple reason: I want to spend my time writing content, not messing about with server maintenance or blog engine updates. If I was making the same decision today I might choose Jekyll or Ghost instead but WordPress.com was just easy and I have no reason to change. Well, maybe one reason…
Security has always been a passion, and these days it is a significant part of my job. I am a fervent supporter of HTTPS everywhere (the concept, not the browser extension) and I recently realised that my blog was not only served without HTTPS by default but it failed with certificate warnings when accessed via HTTPS. My first thought was to bump up my WordPress.com plan to something with TLS support but when I went looking for this option I found that not only do WordPress.com not offer this, they have published some dangerous misinformation about their HTTPS support.
I wanted to avoid going through the effort of migrating my blog to new hosting. All I really needed was to put an intelligent HTTPS proxy in front of my existing blog. Conveniently that is a core component of what my team and I have been building this year: section.io. In short, section.io is a HTTP-reverse-proxy-as-a-service solution focused on a providing a great DevOps story. At the moment it is predominantly used for Varnish Cache cloud-hosting but its capabilities are growing rapidly.
With section.io I was able to register a new, free account and within about 3 minutes the infrastructure had been provisioned to proxy my WordPress.com-hosted blog through a default configuration of Varnish 4. For now, because WordPress.com do their own caching, and I want to focus on writing blog content, I’m leveraging Varnish only for response header manipulation, not caching.
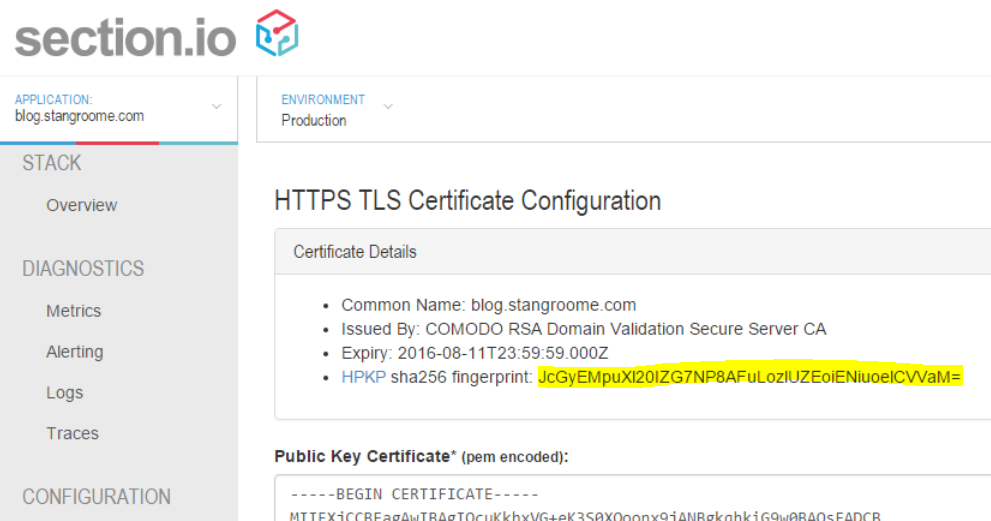
Also, because Varnish Cache (and inevitably other proxies that section.io will support one day) doesn’t have native HTTPS support, section.io provides a thin TLS-offload layer in front of Varnish, all I need to do is upload a certificate. For recent years, my DNS host and registrar of choice is DNSimple and they now sell TLS certificates too. Through DNSimple, I bought a Domain Control Validated certificate for only US$20 for the year, which is then issued by Comodo.
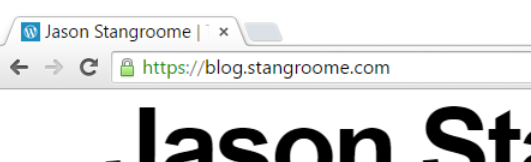
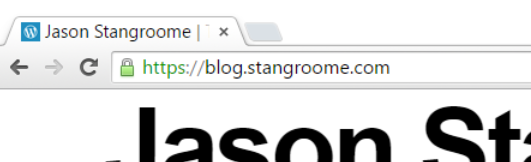
I uploaded my new certificate and private key into the section.io management portal and moments later my blog could be accessed via HTTPS and I was greeted with a friendly green padlock. I should point out that the free HTTPS support on section.io does not support non-SNI capable user agents at this time but I’m comfortable ignoring that quickly shrinking pool of browsers for my blog.
Merely being able to access my blog via HTTPS is not enough however, I want it to be accessed only via HTTPS so that requires a little more work, but its all achievable with a little bit of Varnish Configuration Language.
section.io strives to provide the same unconstrained Varnish experience one would get from hosting Varnish themselves. In this instance, I get access to the default.vcl file in my own section.io account’s git repository, and a convenient web-based editor to make quick changes.
The first change is to add some VCL to detect whether the request was made without HTTPS, by inspecting the conventional X-Forwarded-Proto header, and respond with a synthetic 301 Moved Permanently response to the HTTPS URL as appropriate:
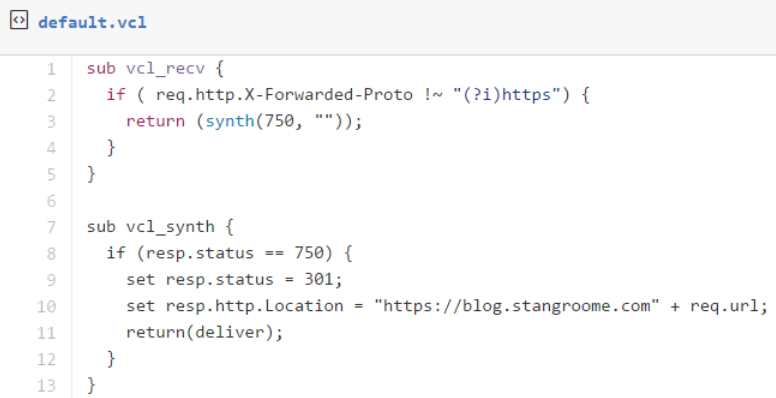
The second change is to add HSTS response headers so that return visitors will automatically use HTTPS for all requests without needing the server-side redirect:

At this point section.io is configured to serve my blog as HTTPS-only but public traffic is still hitting WordPress.com directly. When I registered my blog site with section.io I was provided with a new CNAME value to configure my blog’s DNS to resolve to. I didn’t change over immediately though, I used Fiddler (or my local HOSTS file) to simulate the change and verify I had everything working right. I’ve since changed my public DNS records and you should now be reading this post over HTTPS.
Troy Hunt has recently blogged about the generally “premium” nature of TLS being a blocker of wider HTTPS adoption, and he is right, but there are a number of more affordable solutions growing in response to the increasing demand. What I have found though is that the cost of certificates and hosting is quickly surpassed by the knowledge required to implement HTTPS right because it is so much more than just getting a key pair and talking HTTP through an encrypted tunnel.
A good HTTPS deployment needs to consider TLS protocol versions and cipher suites, needs to avoid mixed-mode content, and utilise HPKP, which I’ll be configuring on my blog soon. Some of this will hopefully be handled by your hosting provider but a lot also crosses over into the application domain.